Using AI (artificial intelligence) for software design and development has firmly become part of day-to-day work. At some point it became clear to me that no matter how powerful a large language model (LLM) is, the completeness and accuracy of the provided context are crucial.
As a product-minded developer working in a company setting, I almost always think about development in the context of a team. We have code reviews and formal documentation, but when it comes to generating code or reviewing it with AI, I see a wide gap between “smart tools” and the existing knowledge base. I like the phrase “AI doesn’t know what people need”, and it’s oddly amusing to watch how people keep waiting for ever more autonomous tools.
Let’s begin!
Documentation FOR AI only
Not for yourself. Not for your boss. Not for a human.
The approach is this: we write and shape our documentation for a single audience—AI. In some places the wording can be shorter; elsewhere it can be more verbose. The single goal: improve the quality of the AI agent’s work. We ignore stylistic preferences and subjective polishing—technical documentation is a prompt.
Why does this matter?
Verifiability
When we write exclusively for AI, we get a built-in feedback loop on quality: if the documentation is poor, the answers will be mediocre. That’s a strong advantage in practical areas like code review and code generation.
Motivation
If you—or a teammate—manage to improve an agent’s output with documentation, you can share it. Contributing to a calibration that others can verify is, in my view, the best motivation to write docs.
A strict format
Documentation geared toward AI is rapidly evolving:
- Memory bank (“Who am I and what did we do before?”) — the agent’s long-term, personalized memory. Helps continuity across sessions.
- Context portal (“What do we have on this topic?”) — a structured project context focused on cross-project documentation and search.
It’s good to know what to write. It’s even better to know how to structure it—and why.
Technical descriptions usually capture facts answering: “what is it?”, “how is it built?”, and “how do we use it?”. In other words, they record solution details more often than the reasons behind them.
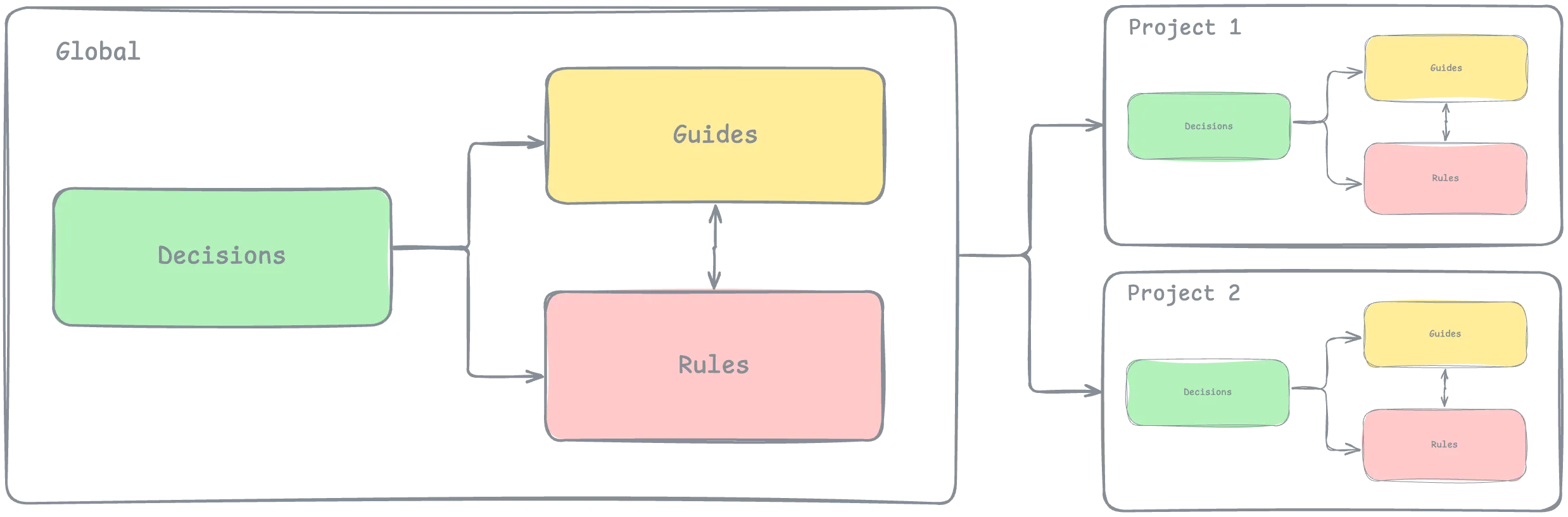
My documentation concept relies on four artifact types: Decisions, Rules, Guides, and Projects. These let you reflect both the reasons behind choices and the resulting rules and instructions.
Decisions
This artifact type is essential for capturing the “why.” I introduce two well-known formats into the technical docs: RFC and ADR.
RFC (Request for Comments)
An RFC (a proposal) is created to outline the available solution options. For the team, it’s useful to record why a particular option was chosen; for AI, it can become strong constraint context.
Markdown template for an RFC:
---
name: 0003-rfc-name # Unique identifier for the RFC
title: RFC Title # Human-readable title
status: accepted # accepted, rejected, draft
tags: [tag1, tag2] # Categorization tags
related: # Cross-references to related documents (one or many)
rfcs: [0001-rfc-name] # Related RFCs by name
adrs: [0001-adr-name] # Related ADRs by name
rules: [rule-name] # Related rules by name
guides: [guide-name] # Related guides by name
projects: [project-name] # Related projects by name
---
## Summary
Who needs it and what changes in one paragraph.
## Context and problem
Current behavior/limitations, scope of impact.
## Proposed solution
- Architectural idea (1-3 bullet points).
- API/contracts (brief, code block if necessary).
- Data/schema/migrations (one-two sentences).
## Alternatives
Why not X and Y (one sentence per alternative).
## Impact
- Performance/cost
- Compatibility/migrations
- Security/privacy
## Implementation plan
Milestones with estimates: M1, M2, M3. Rollback plan in one sentence.
## Success metrics
How we will understand what worked (numbers/threshold/date).
## Risks and open questions
A short listAn example of where an RFC sits in the repository structure is available here.
ADR (Architectural Decision Records)
ADR can look similar to RFCs, but I recommend using them to document the details of the direction already chosen in an RFC.
Learn more about Architectural Decision Records.
A simple markdown template for an ADR:
---
name: 0003-adr-name # Unique identifier for the ADR
title: ADR Title # Human-readable title
status: accepted # accepted, rejected, draft
tags: [tag1, tag2] # Categorization tags
related: # Cross-references to related documents (one or many)
rfcs: [0001-rfc-name] # Related RFCs by name
adrs: [0001-adr-name] # Related ADRs by name
rules: [rule-name] # Related rules by name
guides: [guide-name] # Related guides by name
projects: [project-name] # Related projects by name
---
# ADR Title
## Context
What is the issue that we're seeing that is motivating this decision or change?
## Decision
What is the change that we're proposing and/or doing?
## Consequences
What becomes easier or more difficult to do because of this change?It’s worth noting that even if the team or company hasn’t accepted an RFC/ADR or it’s stuck in draft, that status can still be useful context for AI. ADRs in this documentation structure can be found at this link.
Rules
Rules are imperatives derived from decisions. They state what must and must not be done. When creating rules, you should always reference RFCs/ADRs and other document types. This artifact is very natural for AI and is already used in tools like Cursor as “rules.”
Example:
---
name: unit-test-frameworks # Unique identifier for the rule
title: Unit tests framework # Human-readable title
tags: [tag1, tag2] # Categorization tags
related: # Cross-references to related documents (one or many)
rfcs: [] # Related RFCs by name
adrs: [] # Related ADRs by name
rules: [] # Related rules by name
guides: [] # Related guides by name
projects: [] # Related projects by name
---
# Unit tests framework
For all new projects and when updating existing ones:
1. use Vitest as the primary testing framework
2. migrate from Jest to Vitest when possibleGuides
Guides reference decisions and rules and describe implementation and usage details. This format is harder to standardize and will likely vary by project. In software systems, guides often document how to use modules and other abstractions.
For example, if you build your own software development kit (SDK), guides can include developer docs: how to install, use, and maintain it. You can go further and describe how to build entire modules or systems with your SDK. Natural candidates here are README files. Guides can also cover: stack and architecture overviews, development approaches, coding conventions, and project structure.
Sample guide contents (not a template):
---
name: auth-quickstart
title: Auth SDK Guide (Short)
status: active
version: 1.0.0
tags: [sdk, auth]
related:
rfcs: [0001-auth-rfc]
adrs: [0002-auth-adr]
rules: [use-oauth2, no-plaintext-secrets]
guides: []
projects: [payments]
---
# Auth SDK Guide (Short)
> **Purpose:** Help services obtain and use access tokens via the Auth SDK.
> **Audience:** Service developers. **Outcome:** A working call authenticated with a bearer token.
## Quick Start
**Requirements**
- Node.js ≥ 20
- `AUTH_BASE_URL`, `AUTH_CLIENT_ID`, `AUTH_CLIENT_SECRET`
**Install**
<code>
npm i @acme/auth-sdk
</code>
**Minimal example**
<code>
import { AuthClient } from "@acme/auth-sdk";
const auth = new AuthClient({
baseUrl: process.env.AUTH_BASE_URL!,
clientId: process.env.AUTH_CLIENT_ID!,
clientSecret: process.env.AUTH_CLIENT_SECRET!,
timeoutMs: 5000,
retries: 3
});
const token = await auth.getToken({ scope: "payments:write" });
client.setBearerToken(token.access_token);
</code>
## Configuration
| Key | Default | Range | Notes |
| ---------------- | ------- | ---------- | ------------------------ |
| `TIMEOUT_MS` | 5000 | 1000–15000 | HTTP client timeout (ms) |
| `RETRY_ATTEMPTS` | 3 | 0–5 | Exponential backoff |
## Constraints
- Based on **RFC 0001** and **ADR 0002**.
- Do not log secrets; mask sensitive fields.
- Token TTL ≤ 60 minutes; cache in-process only.
- Rate limit: ≤ 10 RPS per client.Projects
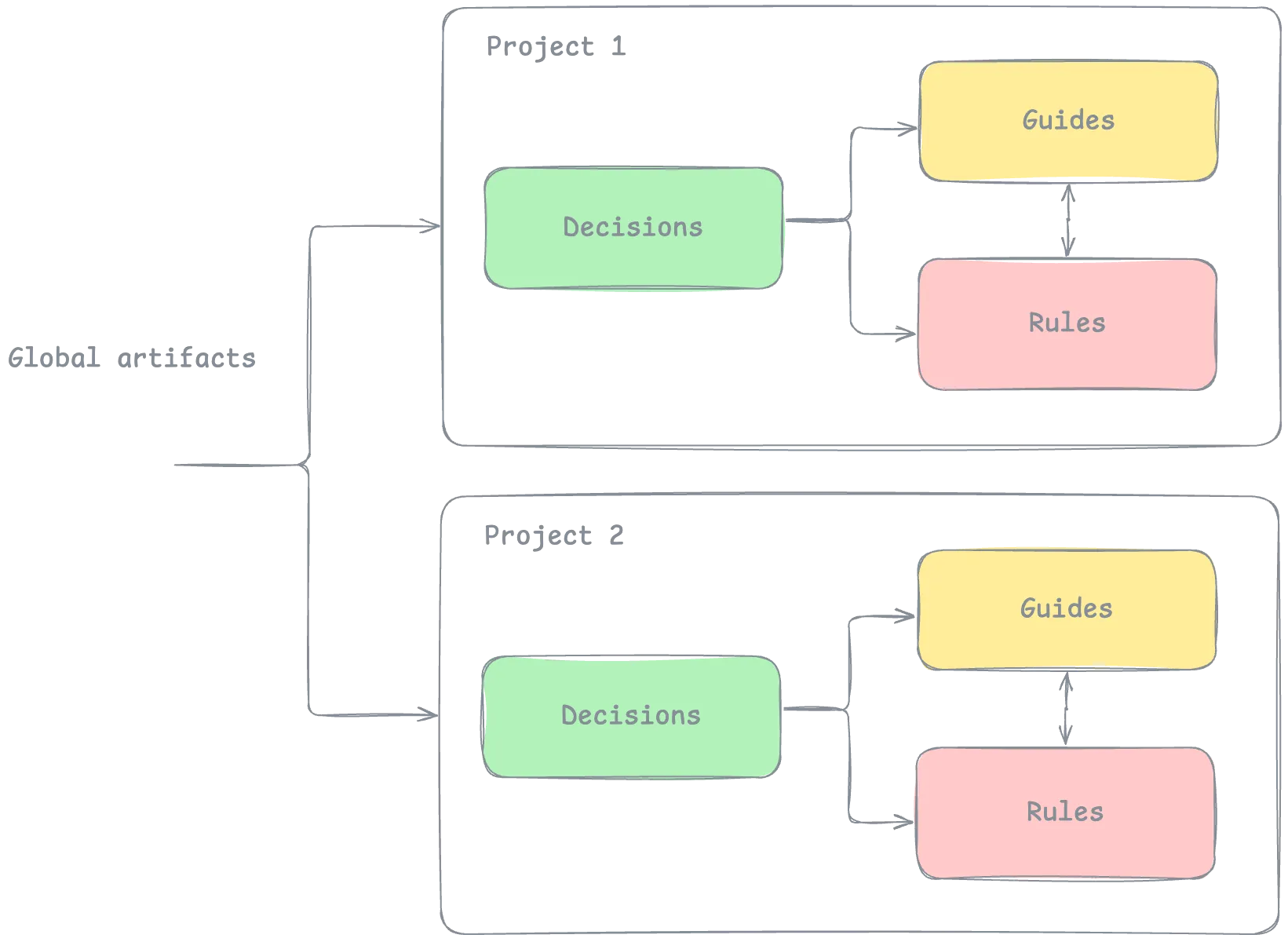
The Projects section (and folder) contains documentation for specific projects. Projects repeat the same structure described above: decisions, rules, guides. In the front matter of md/mdx files you can reference global artifacts and documents from other projects. The key difference is that each project folder includes a project.md.
context1000
context1000 is a documentation format for software systems designed to integrate with AI tools. The key artifacts are ADRs and RFCs, linked by explicit relationships.
This project is an example of a context portal and consists of two parts:
- The documentation format (@context1000/docs)
- A simple RAG (retrieval-augmented generation) for this format that you can run locally.
@context1000/docs
In the repository @context1000/docs you’ll find the concept description and a simple markdown template. If you want a ready-made documentation portal with the context1000 structure, use the templates (Docusaurus, Mintlify).
context1000 (RAG)
RAG is an excellent way to build a context portal. It converts context1000 documentation into a vector database for full-text search by an agent. To expose it to an agent, we use the Model Context Protocol (MCP).
In my implementation, MCP provides the following tools:
- check_project_rules — validates project rules; intended for early agent runs.
- search_guides — search within guides (how-tos).
- search_decisions — search within decisions (ADRs, RFCs).
- search_documentation — a general search across all documents; a fallback.
Conclusion
People don’t need documentation—they need answers.
Two key ideas:
- Documentation FOR AI only — invent better ways to verify documentation quality.
- Architectural artifacts — well-known formats help reduce noise in your documentation.
This article doesn’t cover the implementation details of RAG+MCP for context1000—you can find all the source code in the repository.